
Ce que j'ai pigé de la différence entre Regression et Classification
Ce que j'ai pigé de la différence entre Regression et Classification

Quelle est la différence entre ces deux types ?
Donc commençons avec la régression linéaire
Alors si j’imagine un cas d’utilisation
Tout d’abord, j’ai besoin de construire mon dataset
Il est temps de créer le model
Bon
Comme j’indiquais dans un autre post, il y a deux types (à ma connaissance) d’algorithmes en apprentissage supervisé.

Quelle est la différence entre ces deux types ?
Eh bien, j’ai trouvé un post qui a l’air de résumer :
The main difference between them is that the output variable in regression is numerical (or continuous) while that for classification is categorical (or discrete).
Clair, net et précis.
Pour ce qui est des valeurs continues et discrètes, c’est une histoire d’intervalle de données. Je m’explique.. enfin nan voilà un petit copier/coller qui explique.
On dit qu’une variable est
continue si elle prend un nombre infini de valeurs réelles possibles à l’intérieur d’un intervalle donné. Prenons la taille par exemple. La taille ne peut pas prendre n’importe quelle valeur. Elle ne peut pas être négative, ni être plus grande que trois mètres. Mais le nombre de valeurs possibles que peut prendre la taille est théoriquement infini. Un élève pourrait mesurer 1,632 174 875 5… mètres par exemple. Il s’agit donc d’une variable continue.
discrète ne peut prendre qu’un nombre fini de valeurs réelles possibles à l’intérieur d’un intervalle donné. La note accordée par un juge à un gymnaste lors d’une compétition est un exemple de variable discrète : la plage varie de 0 à 10 et la note ne comporte jamais plus qu’une décimale (p. ex., une note de 8,5). On peut donc énumérer toutes les valeurs possibles (0, 0,1, 0,2…) et constater que le nombre de valeurs possibles est fini : il est de 101 !
Donc commençons avec la régression linéaire
J’ai trouvé un article qui explique super clairement :
Une régression a pour objectif d’expliquer une variable Y par une autre variable X. Par exemple on peut expliquer les performances d’un athlète par la durée de son entraînement.
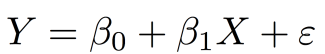
β0 et β1 sont les paramètres du modèle
ε l’erreur d’estimation
Y variable expliquée
X variable explicative.
Dans ce cas on parle de régression linéaire simple car il y a une seule variable explicative. Ainsi on parlera de régression linéaire multiple lorsqu’on aura au moins deux variables explicatives.
Alors si j’imagine un cas d’utilisation
En ce moment c’est la coupe du monde, je peux imaginer collecter les informations sur les joueurs et, via un algorithme de régression, chercher à prédire les revenus du joueur.
Et, pourquoi pas, son niveau de bonheur (sur 10, par exemple) via de la classification. Ce qui pourrait permettre d’anticiper les beuveries des joueurs tristes et riches.
Tout ça s’est bien mais place au concret.
Tout d’abord, j’ai besoin de construire mon dataset
En l’occurrence, je vais le créer de toute pièce. Pour ce faire, j’ai juste besoin de deux array.
#age
x = np.array([20, 23, 24, 30, 33, 35]).reshape((-1, 1))
#revenue
y = np.array([100000, 120000, 150000, 240000, 250000, 260000])La petite subtilité étant que j’ai besoin de reshape mon premier array de sorte à savoir 1 colonne et autant de lignes que nécessaire (c’est le -1 qui joue ce rôle). Une colonne parce qu’il s’agit de l’axe des ordonnées.
Bien sûr j’ai inventé ces valeurs. J’ai donc :
le revenu en abscisse
l’âge en ordonnée.
Uniquement deux variables parce qu’on est sur de la régression linéaire et non de la régression polynomiale. Faut pas pousser pour commencer.

Ensuite passons aux choses sérieuses.
Il est temps de créer le model
Rien de plus simple.
model = LinearRegression()J’aurais pu lui donner le paramètre fit_intercept qui permet de calculer le point d’interception de la droite sur l’axe des ordonnées mais par défaut il est à True.
Il existe d’autres paramètres mais à mon niveau de chômeur, inutile de tout complexifier je pense.
Maintenant ce model doit fitter :
model.fit(x, y)C’est à ce moment que la magie opère. C’est-à-dire que l’algo cherche à calculer la droite !
On peut donc voir le point d’interception et le slope :
print(f"intercept: {model.intercept_}")
print(f"slope: {model.coef_}")Une chose intéressante que je viens de découvrir : Quand un attribut a un underscore, cela signifie que la valeur est estimée.

J’ignore si c’est si intéressant que ça mais je préfère le noter malgré tout.
Et maintenant on peut prédire
Je ne sais pas quoi dire. J’obtiens [111101.92837466] pour 21 et si on regarde la courbe sur le graphique ça se tient.
y_pred = model.predict([[21]])
print(f"predicted response:\n{y_pred}")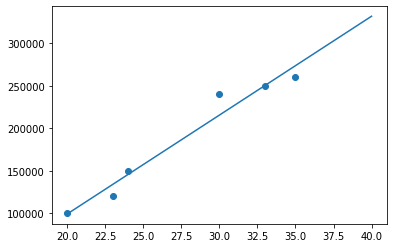
Maintenant ai-je bien tout fait dans les règles de l’art ? Certainement pas mais on a le temps de découvrir ces erreurs.
Pour faire comme les professionnels, j’ai tout de même envoyé mon code sur un repo Github.
Restera à tester pour de la classification une prochaine fois.